Default, General Function for Computing Treatment Effects with Panel Data
Source:R/pte.R
pte_default.RdThis is a generic/example wrapper for a call to the pte function.
This function provides access to difference-in-differences and unconfoundedness based identification/estimation strategies given (i) panel data and (ii) staggered treatment adoption
Usage
pte_default(
yname,
gname,
tname,
idname = NULL,
data,
panel = TRUE,
xformula = ~1,
d_outcome = FALSE,
d_covs_formula = ~-1,
lagged_outcome_cov = FALSE,
est_method = "dr",
anticipation = 0,
base_period = "varying",
control_group = "notyettreated",
weightsname = NULL,
cband = TRUE,
alp = 0.05,
boot_type = "multiplier",
biters = 100,
cl = 1,
...
)Arguments
- yname
Name of outcome in
data- gname
Name of group in
data- tname
Name of time period in
data- idname
Name of id in
data- data
balanced panel or repeated cross sections data
- panel
Whether the data are panel data. The default is TRUE. Set to FALSE for repeated cross sections.
- xformula
one-sided formula for covariates used in the propensity score and outcome regression models
- d_outcome
Whether or not to take the first difference of the outcome. The default is FALSE. To use difference-in-differences, set this to be TRUE.
- d_covs_formula
A formula for time varying covariates to enter the first estimation step models. The default is not to include any, and, hence, to only include pre-treatment covariates.
- lagged_outcome_cov
Whether to include the lagged outcome as a covariate. Default is FALSE.
- est_method
Which type of estimation method to use. Default is "dr" for doubly robust. The other option is "reg" for regression adjustment.
- anticipation
how many periods before the treatment actually takes place that it can have an effect on outcomes
- base_period
The type of base period to use. This only affects the numeric value of results in pre-treatment periods. Results in post-treatment periods are not affected by this choice. The default is "varying", where the base period will "back up" to the immediately preceding period in pre-treatment periods. The other option is "universal" where the base period is fixed in pre-treatment periods to be the period right before the treatment starts. "Universal" is commonly used in difference-in-differences applications, but can be unnatural for other identification strategies.
- control_group
Which group is used as the comparison group. The default choice is "notyettreated", but different estimation strategies can implement their own choices for the control group
- weightsname
The name of the column that contains sampling weights. The default is NULL, in which case no sampling weights are used.
- cband
whether or not to report a uniform (instead of pointwise) confidence band (default is TRUE)
- alp
significance level; default is 0.05
- boot_type
should be one of "multiplier" (the default) or "empirical". The multiplier bootstrap is generally much faster, but
attgt_funneeds to provide an expression for the influence function (which could be challenging to figure out). If no influence function is provided, then theptepackage will use the empirical bootstrap no matter what the value of this parameter.- biters
number of bootstrap iterations; default is 100
- cl
number of clusters to be used when bootstrapping; default is 1
- ...
additional arguments passed to
pte, such asmin_e,max_e, andbalance_efor controlling the event study range.
Examples
# example using minimum wage data
# and a lagged outcome unconfoundedness strategy
library(did)
data(mpdta)
lou_res <- pte_default(
yname = "lemp",
gname = "first.treat",
tname = "year",
idname = "countyreal",
data = mpdta,
xformula = ~lpop,
d_outcome = FALSE,
d_covs_formula = ~lpop,
lagged_outcome_cov = TRUE
)
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: non-integer #successes in a binomial glm!
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
#> Warning: critical value for uniform confidence band is somehow smaller than
#> critical value for pointwise confidence interval...using pointwise
#> confidence interal
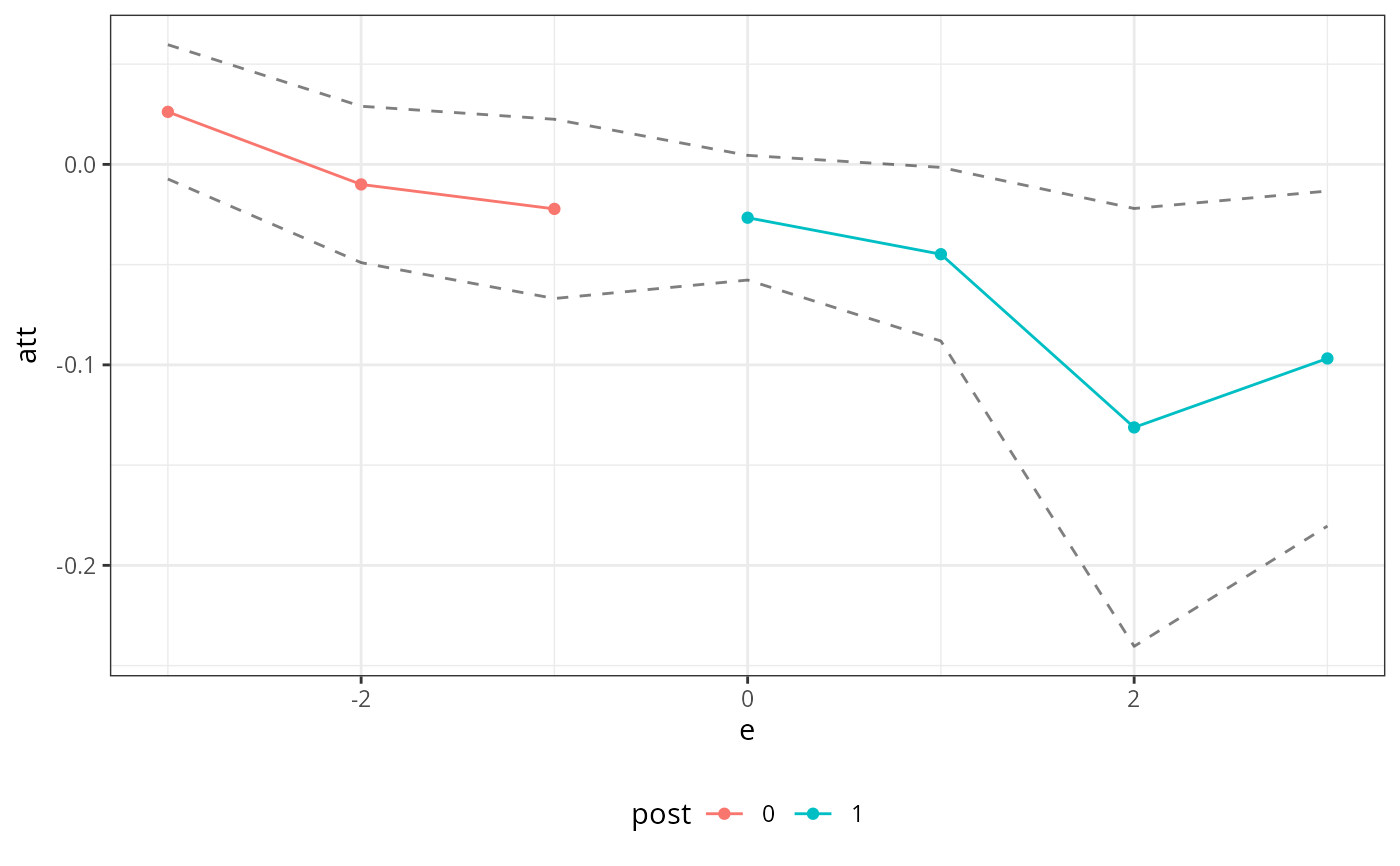
summary(lou_res)
#>
#> Overall ATT:
#> ATT Std. Error [ 95% Conf. Int.]
#> -0.037 0.0126 -0.0618 -0.0122 *
#>
#>
#> Dynamic Effects:
#> Event Time Estimate Std. Error [95% Simult. Conf. Band]
#> -3 0.0262 0.0130 -0.0073 0.0597
#> -2 -0.0100 0.0151 -0.0490 0.0290
#> -1 -0.0222 0.0173 -0.0669 0.0225
#> 0 -0.0266 0.0120 -0.0577 0.0045
#> 1 -0.0448 0.0167 -0.0881 -0.0015 *
#> 2 -0.1312 0.0422 -0.2404 -0.0220 *
#> 3 -0.0968 0.0323 -0.1804 -0.0133 *
#> ---
#> Signif. codes: `*' confidence band does not cover 0
#>
ggplot2::autoplot(lou_res)